If you have not read the previous article of “Nuts & Bolts of Tally Filesystem: Embedded Indexing”, Please do so for a better understanding of this part, otherwise you will feel like your friend has bluffed you into watching a sequel of a movie without watching the previous part of it.
As it was already mentioned in the previous article, “The tally db is one of the multiple phoenixes of the tally product, that keeps rediscovering itself to keep pace with the raising requirements of the ever-emerging Tally product to simplify how you run your businesses.”
Whenever a new data pattern is identified in Tally product, without a second thought we at Tally will start the work of re-discovery and one such opportunity came in the form of GST. We identified multiple data patterns with the advent of GST regime, and one such data pattern gave rise to RangeTree.
With the advent of GST, Tally wanted to deliver a user friendly gst tax compliance experience. But the caveat being it must be done as soon as possible so that Tally users can start following the tax compliance from the day1 of its mandate. Multiple new use cases have come up and one of it is GST reports. Functionally Tally was able to deliver the gst reports that were delivering all the data that’s needed by the tally users in the initial GST releases of Tally but the feedback from the market on the time taken to populate the GST reports has been on top of the list to be solved or improved upon.
For Rel3.0 of tally we truly desired to make GST reports faster and delightful to see our Tally users happy and have more productive time at running their businesses.
What was happening when GST reports are opened:
To generate GST reports, most of the time was going into computing the data, voucher wise and deciding on their individual applicability for different GST buckets. But these computations were necessary to have Fresh and up to date status of GST returns as and when the reports are accessed.
Should we do the computations even before we enter the GST reports? Ok if we can do the pre-computations when vouchers are created or altered and store them on the disk such that reports can be rendered faster as the computations will be readily available.
But what is the validity or freshness of these pre-computations when the maters used in the vouchers are altered. For e.g.: the stock item used in the voucher has undergone a change in tax category and GST rate details are altered. When such alterations happen in the master’s then the pre-computations done depict stale values.
So doing pre-computations will make reports faster but how to manage the master alterations that can make these pre-computations stale.
Whenever a master is altered, shall we make a list of vouchers that the master is participating and do re-computations but that way each master alteration will take a lot of vouchers to complete. Can we update the pre-computation later and accept the master as is for now? This would allow the subsequent vouchers getting created or altered have up to date pre-computations. Now the only problem that was left out was how to update the vouchers that have already been created or altered before the master alteration.
Now whenever a master alteration is done if we can mark all the existing vouchers as stale, they can be picked up for ‘re-computation later’ in worst case just before populating GST reports. But this would involve a lot of io to read each voucher and mark them as stale and this would make a master alteration a time taking operation.
So now we wanted faster GST reports and at the same time it should not have any side effects on the current functionalities like master alteration. To add another level of complexity there can be multiple master alterations in each cycle and doing re-computations in isolation for same vouchers again and again is redundant and effects productivity. If we can store the references to a given set of vouchers getting affected by a master alteration and keep adding more vouchers to the set upon other master’s alterations will avoid redundancy of voucher re-computations.
Can Embedded Indexing be used in all use cases?
In the current TPFS [Tally proprietary File System] the records are connected to each other via embedded tree links and to mark all the vouchers using a master will require us traverse each of these vouchers and mark them as stale. Like this we should do for all the master’s that will go through alterations before we access the GST reports.
This marking itself will lead to a lot of io's as we need to read the vouchers mark them and persist them.
Moreover, when we want to do re-computation of the affected voucher to know which all vouchers are marked as stale requires us to walk all the vouchers in the company and then check each voucher for staleness and then take it up for re-computation.
So, the main problem with this approach is more io's and in turn more time.
To simplify the problem statement: when a master [ledgers, stock items for that matter all the elements that participate in a financial transaction are called masters] is altered, vouchers that are using this master may be impacted and so these vouchers are to be recomputed.
Let’s say vouchers with below id’s are impacted by altering a master m1:
1, 2, 3, 4, 5, 34, 36, 38, 39, 45, 56, 57, 89, 357, 358, 415, 568, 569, 790, 857, 858, 859, 923, 1023, 1024, 1059, 1067, 1256, 1267…….
Below id’s are impacted by altering another master m2:
91, 92, 198, 199,200, 201, 203, 204, 345, 356, 412, 413, 418, 567, 570, 789, 856, 934, 935, 936, 937, 1025, 1026, 1027, 1039, 1057, 1200, 1259, 1268…………………
this way when multiple masters are altered vouchers that are getting impacted keep accumulating.
Taking steps towards the solution:
By keeping index into the records, the records become dirty and needs to be written to disk. Writing to disk consumes time and in turn increase the time to complete the user operation. In this case when master is altered then indexes are to be embedded into all the vouchers that are impacted
due to this alteration. Due to this all the voucher records that become modified due to the embedded indexes are to be written to disk in turn increasing the time taken to accept a master. This will impact the master acceptance time which is a day-to-day operation while using Tally.
Maintaining a separate list of voucher identifiers might be a solution. To further optimize the usage of disk usage to maintain the list of voucher identifiers, can a bit map be used?
BitMap and its geography:
A bit map is a virtual interpretation of bits in such a way that the position of the bit can be used as a representation of the corresponding identifier’s value.
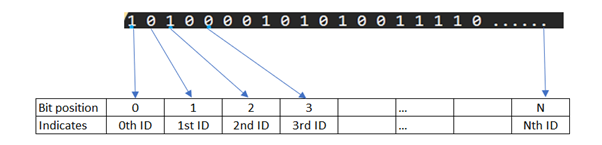
What will be the maximum size of bitmap in this use case:
The bitmap is theoretically should support the maximum range of the identifier which it is representing, in this case the unique identifier of the voucher let’s call it voucher id.
The voucher id is of 4 bytes length due to technical reasons of the language in which the product has been coded.
- Voucher identifier (id) length in tally = 4bytes = 4*8 bits per byte = 32-bit number.
- Biggest voucer id can be 2 Power 32 = 4294967295.
- So ideally one bitmap can grow till (4294967295 / 8 bits per byte) = 53,68,70,911 bytes approximately 511MB.
Bit Map should be able to represent 1 to 2 power 32 (4294967295 ~= 511 MB)

How can a 512-byte Tally block be used to represent the 511MB of data: introducing Leaf Block
Each Tally block of data is of 512 bytes and excluding some of it or header data, lets say 12 bytes of header data we have 500 bytes of disk space for each block to store the actual data.
So, each block can represent 4000 identifiers [500 * 8 bits each]
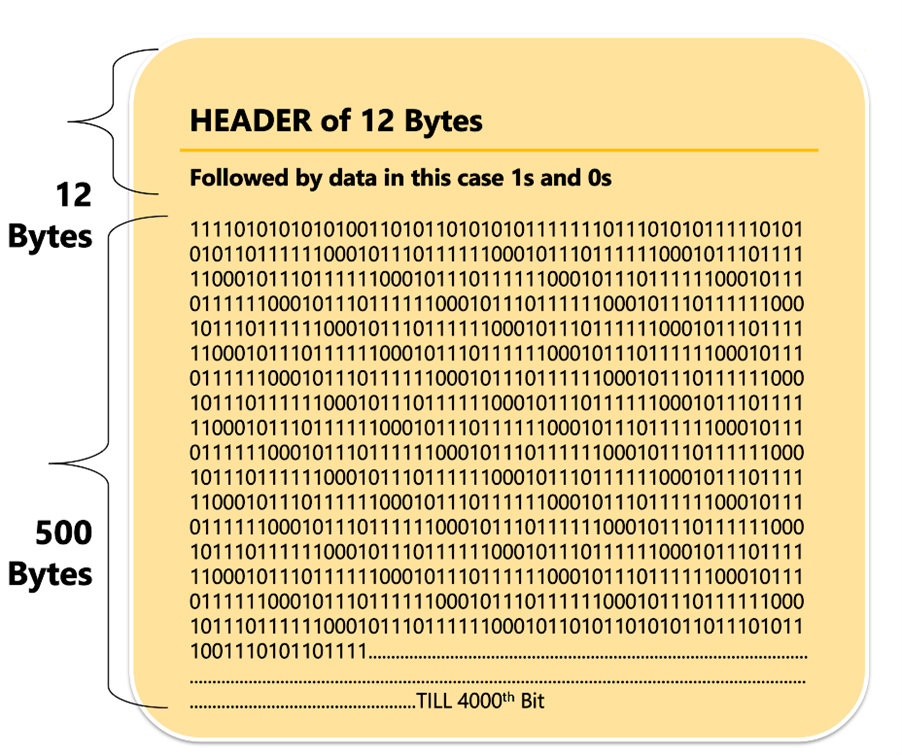
|
Each 512-byte block can represent 4000 bits. A range of 1 – 4000 bits is represented by the 1st block. Range of 4001 – 8000th bit is represented by the 2nd block. And so on… Each of this block is called a “LEAF BLOCK”.
Total number Leaf Blocks to represent 1 to 2 power 32 (4294967295 ~= 511 MB): • 511 MB = 511 * 1024 KB = 511 * 1024 * 1024 Bytes • 511 * 1024 * 1024 Bytes / 500 bytes = 10,71,645 number of blocks. • 10,71,645 number of blocks ~= 10 Lakh leaf blocks. • To reach Leaf blocks we have non-leaf blocks. |
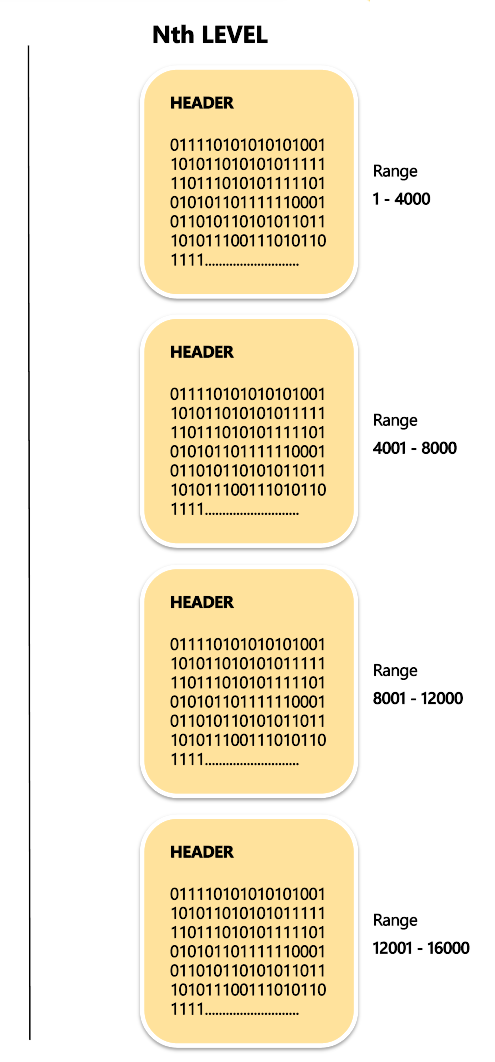 |
How to tame the horses: introducing Non-Leaf Block
Theoretically there are 10Lakh leaf blocks and reaching them on the disk randomly will start impacting the fetch performance. To do the fetch operation in an optimal way we store the offset of the leaf block in another block and more of these offsets of different leaf blocks can be kept into a block which is containing only the offsets to these leaf blocks. This block which is storing all the offsets is called a “NON-LEAF BLOCK”.
4 Bytes of offset i.e., in this (N-1)th level a non-leaf block leaving the block header of 12bytes can store 500bytes / 4Bytes = 125 Offsets.
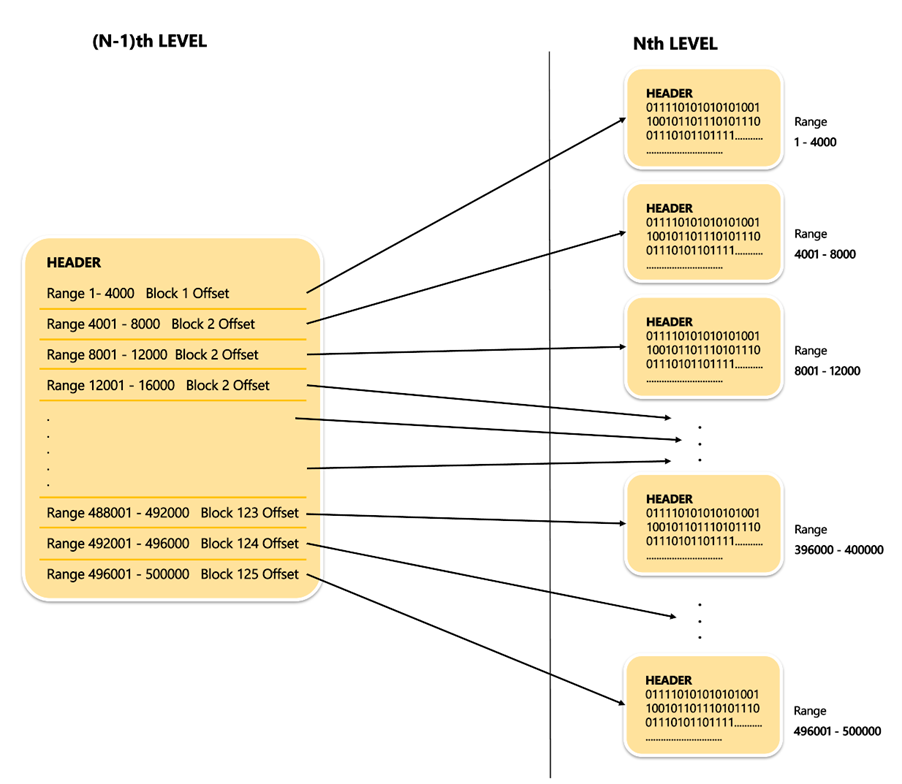
This (N-1)th Level for a full range of 2 Power 32 will look as below :
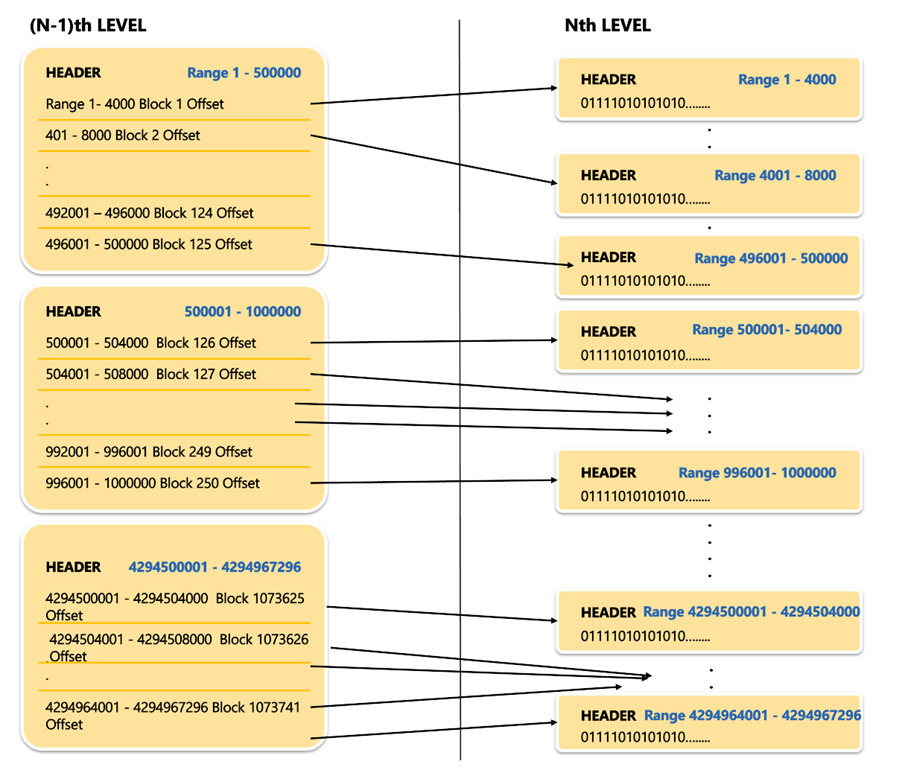
Simplifying the route of reaching out to the required voucher id value:
At each level there will be a challenge of number of blocks being more than 1 and due to this reaching out a specific block needs to be optimized. To do so when a new level is added with non-leaf blocks then around (N-3)rd level we reach a stage where the complete range of 1 - 2^32 can be reached via a reference to one single block which is called as Root Block or the ground zeroth Level block. Using the Root block, we can check if a given voucher id is set to 1 or 0 based on which it will be picked up for re-computation.
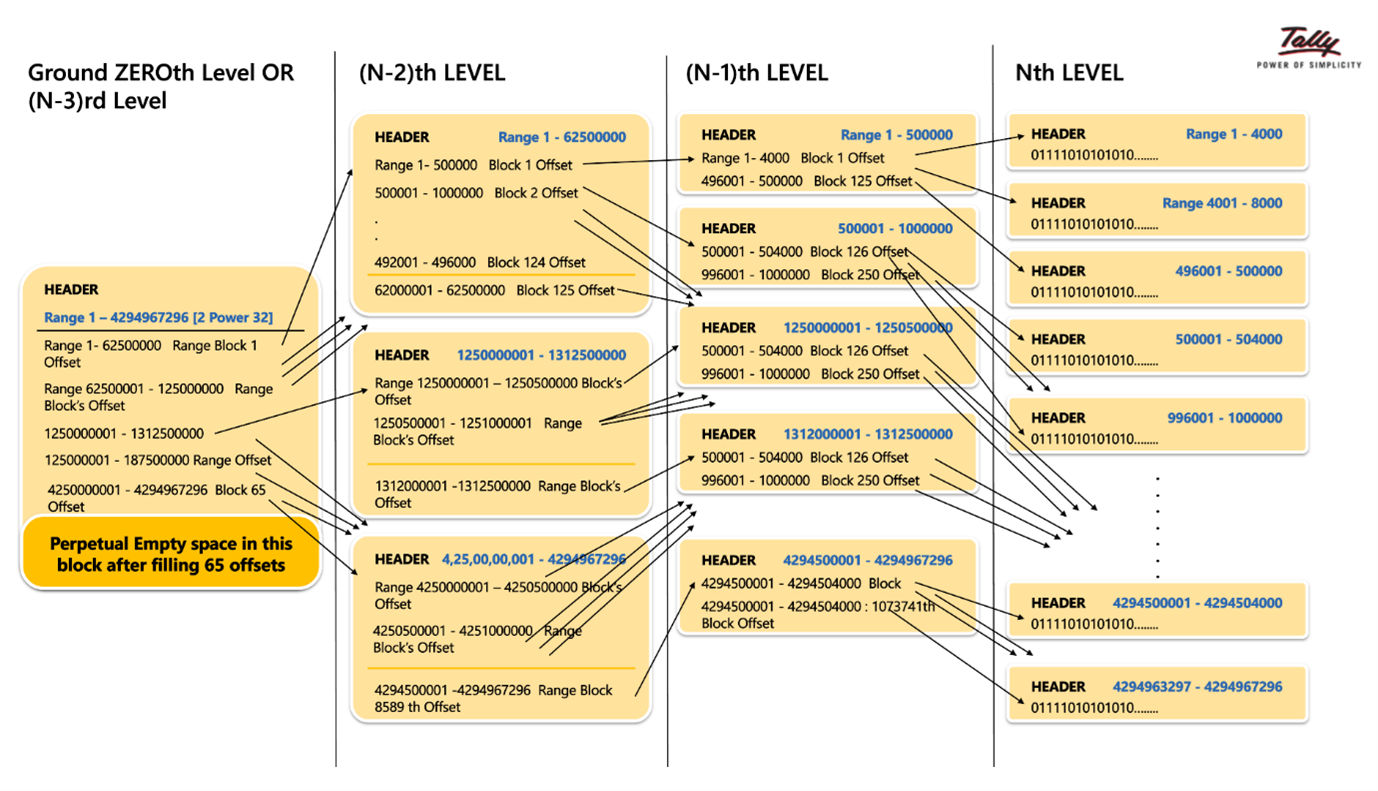
The above RangeTree blocks will only come into existence only and only if the data is present in the respective leaf node path. These blocks at each level are created on demand when a necessity of data storage arises rather than a full blown out complete set of blocks getting created with empty blocks. One such path for easy visualization is below. Only the absolutely necessary blocks are created.
Summing it up:
In scenarios where fetch must be faster, size of data should be smaller, but the participating nodes are dense in nature a Range Tree can be used for both in-memory and on-disk scenarios. In this use case, when a master is altered the vouchers that are using it are marked as to be recomputed in the range tree and when more and more master alterations happens more and more vouchers are marked. A voucher that is already impacted by master1 would have been marked when another master2 is altered. When the Tally business user is ready to do the re-computation, it can be triggered by entering the GST reports. Once re-computation is done and pre-computation are updated the reports whenever accessed will be populated with utmost speed. To fetch/populate the GST reports with minimal input output operations and minimal time, many such optimizations have been done in the product and Range Tree has contributed a small amount of performance optimization to this cause.
We will come back with yet another insightful nugget of another ‘nut and bolt’/data structure, which runs in your tally software to give you the most reliable and speedy experience in your favorite business reports.
Till then wish you lots of Cheers, happiness in learning something New.
Ciao!













