Imagine a tool that can write poetry, translate languages, answer your questions, and even craft code—all while sounding eerily human. Welcome to the world of Large Language Models (LLMs), the AI powerhouses reshaping how we interact with technology. Trained on vast oceans of text, LLMs like GPT-4 and Gemini have become the Swiss Army knives of the digital age, enabling everything from smart chatbots to real-time content creation.
But their brilliance comes at a cost: these brainy behemoths demand colossal computing power, hefty budgets, and specialized infrastructure, leaving many wondering—can we harness their magic without the complexity?
In this article, we’ll unpack why LLMs are revolutionary, explore their hidden challenges, and reveal how Small Language Models (SLMs) are democratizing AI, making intelligence faster, cheaper, and accessible to all. Buckle up—the future of language AI is lighter than you think!
What is an LLM?

A Large Language Model (LLM) is an advanced computer program designed to understand and generate human language. It’s trained on a huge amount of text, like books, websites, and articles, so it learns how language works — such as grammar, sentence structure, and even context.
Because of this training, LLMs can do a variety of tasks, like translating languages, summarizing information, answering questions, and even creating new text. Some well-known examples are GPT (used in tools like ChatGPT), BERT, and T5.
These models are called “large” because they have a huge number of “parameters,” which are like settings that help them understand and produce language in a more human-like way. LLMs are used in things like chatbots, virtual assistants, and other AI-powered tools that help us interact with technology more naturally.
“Basically, an LLM is like an Einstein who not only aces math and physics but also moonlights as a poet, translator, and trivia champion — with a knack for pretty much everything!”
What does it take to run an LLM?
To effectively run a Large Language Model (LLM), several key components are required, each serving a specific purpose that contributes to the overall performance and efficiency of the model. It’s also important to consider the cost implications associated with each component:
- Computing hardware
- Why is it needed: LLMs demand substantial computational resources due to their complexity and the volume of data they process. Depending on the size of the model, this may include:
- CPUs: Sufficient for smaller models or limited tasks.
- GPUs: Essential for larger models to accelerate computations, particularly during training and inference, as they can perform parallel processing on large datasets.
- TPUs: Specialized hardware for training deep learning models, offering even greater performance in certain contexts.
- Cost implications: High-performance GPUs and TPUs can be expensive, with costs ranging from hundreds to thousands of dollars per unit. Additionally, maintaining a powerful server or cloud infrastructure incurs ongoing operational expenses.
- Memory and storage
- Why is it needed: LLMs, especially large ones, require significant amounts of RAM to load the model and process data efficiently. Disk storage is also critical for saving the model, training data, and any additional resources.
- RAM: Sufficient memory allows for handling multiple requests and processing large batches of data simultaneously.
- Disk Space: Adequate storage is necessary to hold the model files, which can be several gigabytes in size, along with datasets used for training or fine-tuning.
- Cost Implications: High RAM and storage solutions can lead to increased upfront costs. Cloud services typically charge based on usage, which can accumulate significantly with larger models and datasets.
- Software frameworks
- Why is it needed: Specific frameworks and libraries facilitate the development, deployment, and execution of LLMs. Common frameworks include:
- TensorFlow and PyTorch: These provide tools for building, training, and running models efficiently.
- ONNX: Useful for optimizing and deploying models across different platforms.
- Cost implications: Most frameworks are open-source and free to use; however, some may require commercial licenses for advanced features or enterprise-level support.
But why does one need to have all these requirements?

Small example on schematics of LLM Internal Architecture
Large Language Models (LLMs) have heavy requirements because of several reasons, including the need for complex calculations like matrix multiplications:
- Size and complexity
- Many parameters: LLMs can have billions of parameters, which are like tiny knobs that the model adjusts during training to understand language. More parameters mean more computing power is needed.
- Deep layers: LLMs consist of multiple layers of processing units. Each layer performs complex calculations for every word or sentence, which adds to the overall demands.
- Matrix multiplications
- Core operations: The main computations in LLMs involve matrix multiplications. When processing text, the model transforms inputs into matrices (tables of numbers) and then multiplies these matrices to generate outputs. This process requires a lot of calculations, especially with larger models.
- Computational intensity: Matrix multiplications are resource-intensive and can be time-consuming, requiring specialized hardware (like GPUs) to perform them quickly.
- Handling large amounts of data
- Big datasets: LLMs are trained on huge amounts of text — often many terabytes. Processing all this data requires a lot of memory and storage.
- Batch processing: To speed up training, LLMs often look at multiple pieces of data at once, which also needs extra memory.
- Understanding language
- Context matters: Natural language is tricky and context-dependent. LLMs need to analyse nuances, like tone and meaning, which requires more calculations.
- Dealing with ambiguity: Words can mean different things depending on the situation. LLMs need to work through these ambiguities, adding to their complexity.
“So one might assume that, We can only work on LLMs if we have super computers!!!” — → But that’s a wrong assumption ! , Let me prove it.
Introducing SLM (Small Language Model)

LLM vs SLM
Small Language Models (SLMs) are simpler versions of Large Language Models (LLMs). They keep some of the important features of LLMs but require much less computing power. While LLMs can have billions of “knobs” (parameters) to adjust, SLMs have fewer, making them easier to run on everyday devices like laptops, smartphones, or even smaller gadgets.
Additionally, from an organizational cost perspective, deploying SLMs can be much more economical. The lower computational requirements mean reduced costs for hardware, energy consumption, and maintenance. This makes SLMs a cost-effective solution for businesses and developers looking to implement AI without the heavy financial burden associated with operating LLMs. By using SLMs, organizations can still provide intelligent applications while saving on infrastructure expenses.
Key features of SLMs
Smaller and simpler
- Fewer parameters: SLMs have fewer parameters than LLMs, which means they are less complex and easier to manage.
- Simpler operations: They often use simpler methods or fewer layers, which allows them to work faster.
Efficiency
- Lower resource needs: SLMs can run on regular hardware, so you don’t need expensive computers to use them.
- Faster responses: Because they are smaller, SLMs can generate answers more quickly, making them great for real-time use.
More accessible
- Wide range of uses: SLMs can be used in many applications, like chatbots or simple text generation, where LLMs would be too much.
- Works on mobile devices: They are perfect for smartphones and other devices that don’t have a lot of processing power.
But, how ?
Converting a Large Language Model (LLM) to a Small Language Model (SLM) involves a series of steps aimed at making the model more efficient and easier to use. Here’s a step-by-step breakdown of how to do this, including techniques like model pruning, quantization, and GGUF.
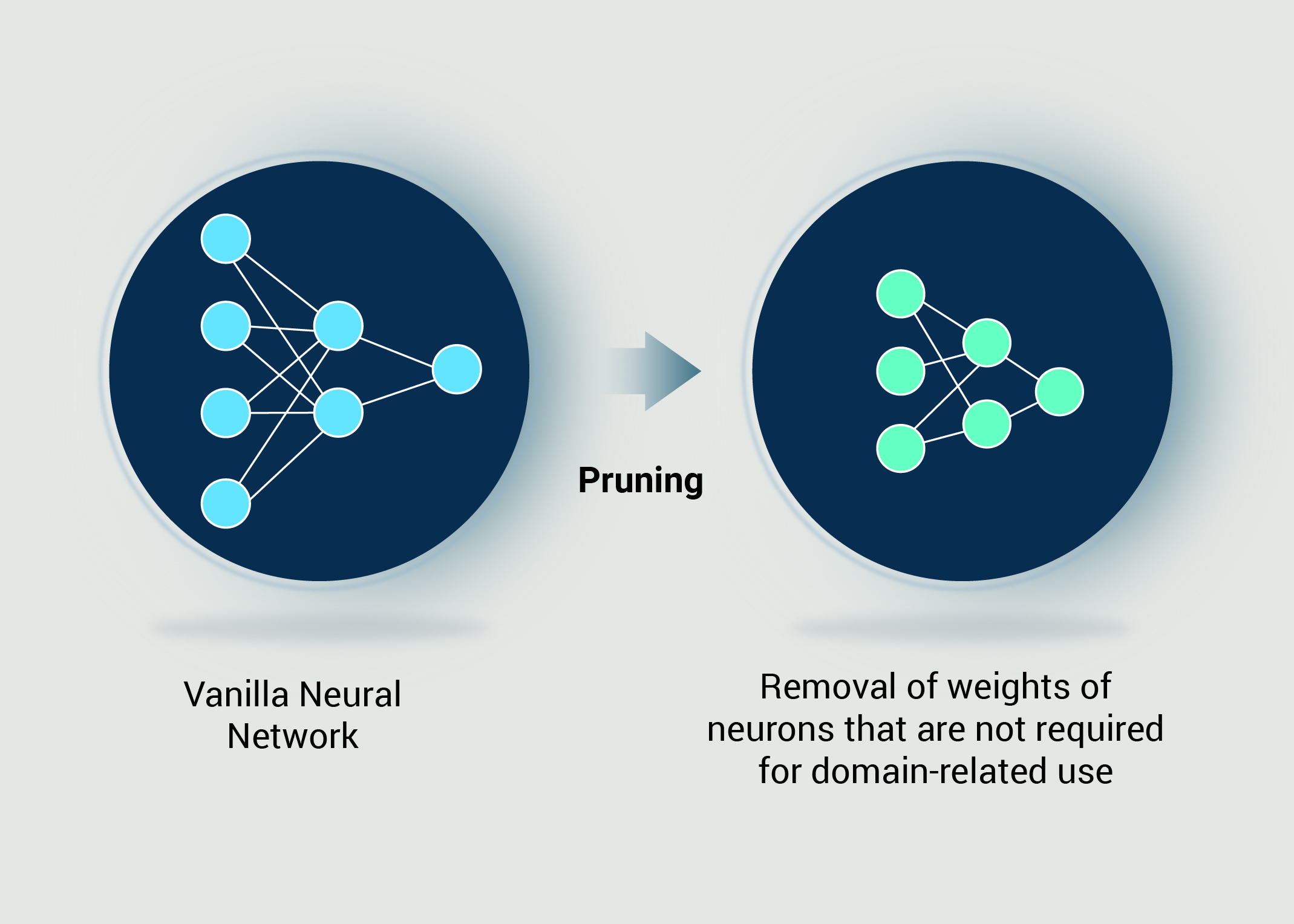
- Model Pruning
- What is Model Pruning?: Pruning involves removing unnecessary or less important parts of the model, such as weights or entire neurons that contribute little to its performance. Imagine trimming a bush: you cut away the branches that don’t add much to the overall shape, making it more manageable. In terms of LLMs, pruning helps to reduce the number of parameters, leading to a smaller model that runs more efficiently without a significant loss in accuracy.
- Use Quantization
- What is Quantization?: Quantization is the process of reducing the precision of the numbers used to represent a model’s parameters. For example, instead of using 32-bit floating-point numbers, you can switch to 8-bit integers. This is like changing a high-definition movie into a lower resolution; it takes up less space and runs faster, but still looks good enough for most people. By using quantization, you can significantly reduce the model’s size and improve its speed.
Solution = Pruning+Quantization
- Implement GGUF (Generalized GPU Unified Format)
- What is GGUF?: GGUF is a newer model format designed to make it easier to run machine learning models on various hardware. It optimizes how models are stored and executed, allowing for better performance on different devices, from powerful GPUs to simpler CPUs. By using GGUF, you can create SLMs that are not only smaller but also more efficient in terms of how they use the available computing resources, making them accessible for everyday use.
Lets have a deeper look into each of the aspects:
- Model pruning
- Overview: Model pruning involves removing parameters from a neural network that contribute little to its performance, resulting in a more compact and efficient model.
Types of pruning:
- Weight pruning: This technique removes individual weights from the model based on a predefined threshold. Weights that are below this threshold (often close to zero) are set to zero, effectively removing them from the computation.
- Neuron pruning: This method involves removing entire neurons or channels from the model that contribute minimally to the output. The selection criteria can be based on metrics like gradient magnitudes or contribution to loss reduction.
Implementation steps:
- Train the original model: Train the LLM to convergence on your dataset.
- Identify prunable weights/neurons: Use techniques such as sensitivity analysis to determine which weights or neurons have the least impact on model accuracy.
- Prune the model: Remove the identified weights or neurons, followed by fine-tuning the model to regain any lost accuracy.
- Iterative pruning: Repeat the process iteratively, gradually pruning more weights while fine-tuning to optimize performance.
- Quantization
- Overview: Quantization reduces the numerical precision of the model’s parameters, decreasing its size and increasing inference speed.
Quantization techniques:
- Post-Training Quantization (PTQ): This method quantizes a pre-trained model without requiring additional training. It involves:
- Mapping: Convert 32-bit floating-point weights to 8-bit integers using a mapping function, often utilizing techniques like Min-Max scaling or K-means clustering.
- Dequantization: During inference, these quantized values are dequantized to perform necessary computations.
- Quantization-Aware Training (QAT): This method incorporates quantization into the training process, allowing the model to adapt to the reduced precision. Steps include:
- Simulating quantization during forward passes in training, and adjusting gradients accordingly.
- Fine-tuning the model with the quantization simulation to mitigate accuracy losses.
Implementation steps:
- Choose a quantization method: Depending on resources, choose between PTQ and QAT.
- Quantize the model: Apply the chosen quantization method to the model.
- Evaluate performance: Assess the model’s accuracy post-quantization. If significant accuracy loss occurs, consider retraining or fine-tuning.
- Adjust and optimize: Iterate on the quantization process to find the best balance between size, speed, and accuracy.
- Implementing GGUF (GPT-Generated Unified Format)
- GGUF (GPT-Generated Unified Format) is a modern file format designed to store models used for inference, especially for large language models like those in the GPT family. Think of GGUF as a convenient way to package and manage complex AI models, making them easier to use and share.
Large Language Models (LLMs) are powerful AI systems capable of understanding and generating human language, but their complexity demands significant computational resources, making them costly and resource-intensive. Small Language Models (SLMs) offer a practical alternative by using techniques like model pruning, quantization, and formats like GGUF to reduce size and resource requirements while maintaining functionality.
This makes SLMs more accessible and cost-effective for everyday devices and applications, democratizing AI technology. As advancements in optimization and hardware continue, the gap between LLMs and SLMs will narrow, enabling broader adoption of intelligent language processing across diverse use cases.













