In the dynamic landscape of business operations, TallyPrime on AWS emerges as a transformative force, empowering over 7,000 businesses with over 22,000 virtual computers as of today to run their businesses with unprecedented flexibility.
Each virtual office becomes a nexus of productivity, housing individual virtual computers equipped with TallyPrime, accessible anytime, anywhere. With 24*7 cloud access, businesses enjoy unlimited usage, offering them the freedom to operate without restrictions.
Virtual offices and virtual computers
With TallyPrime on AWS, every customer is allocated a personalized virtual office with dedicated AWS infrastructure resources. Within this virtual office, customers have the flexibility to add Virtual Computers, replicating the familiar LAN (Local Area Network) environment commonly employed in physical offices.
As a business opens for the day, customers can start their virtual office and make use of TallyPrime to run their business, and as the business concludes its day, customers can either manually shut down their virtual office, or they will be shut down automatically at the end of the day, to ensure customer’s billable resources are conserved.
And the best part? Plans start as low as 600 INR/month per user, making this powerful cloud solution highly accessible, with unlimited usage. Please note, the price is for AWS hosting; a TallyPrime license is required separately.
Navigating the cloud's multi-tenancy model
In the cloud's multi-tenancy model where infrastructure resources are shared among various consumers, it becomes crucial for cloud providers like AWS to prevent any single entity from monopolizing and abusing usage of resources.
AWS combats this through throttling, a double-edged sword which ensures equitable distribution of resources in the cloud, but also limits resources to a tenant with a genuine business use-case such as TallyPrime on AWS.
|
Related Read |
Reliability at scale
To ensure anytime, anywhere access to TallyPrime, it becomes extremely crucial that requests made by users to start or shutdown their virtual offices are served reliably, consistently, and punctually.
While these are formidable challenges on their own, the landscape changes significantly when operating at a massive scale. Every day during the peak hours when businesses are opening or closing, TallyPrime on AWS is presented with a formidable challenge of managing massive farms of infrastructure resources as customers are starting or shutting down their virtual offices.
Designing a reliable solution which works at such massive scale brings a unique complexity and necessitates a level of innovation unprecedented in the realm of AWS India!
Unleashing infinite scale with virtual buildings
The virtual offices in TallyPrime on AWS are housed within virtual buildings, each representing an AWS account responsible for hosting customer PODs. An AWS account comes with various necessary limitations, including restrictions on the number of resources that can be provisioned within it.
To overcome these limits and accommodate an unlimited number of virtual offices, TallyPrime on AWS employs the concept of horizontal scaling, creating a new virtual building for every 1,000 customers.
Asynchronous messaging
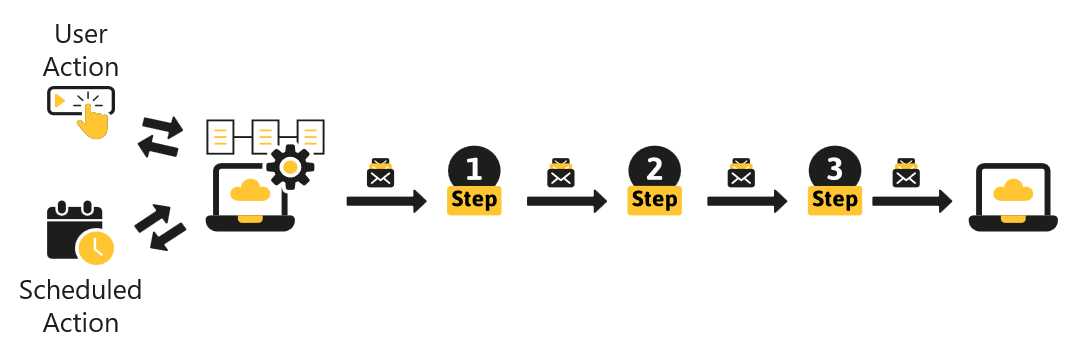
Executing operations on virtual offices like starting, shutting down or updating TallyPrime to a different version requires orchestration of numerous operations that govern the state of various AWS infrastructure resources allocated for each virtual office.
Being a distributed system, TallyPrime on AWS employes asynchronous messaging to ensure the operations performed on virtual offices are executed reliably even at massive scales.

Any operation on a virtual office or a virtual computer, whether it is triggered by a user or by the system, goes through an Operation Pipeline consisting of multiple SQS Message Queues and AWS Lambda Functions.
Communicating at scale
Each lambda function represents an independent, idempotent, retriable, and atomic piece of logic which is a part of serving the user request. To serve the whole user request, lambdas in the pipeline work together by communicating with each other using asynchronous messaging queues as opposed to API calls.
Each lambda has its dedicated inbox of messages (SQS Queue) where messages await their turn. After a message is picked up and successfully processed by a lambda, it moves to the inbox queue of the next step in the pipeline. But in case of any unsuccessful processing of the message due to reasons such as throttling applied by the cloud provider, the message moves back to the same queue for it to be re-retried with an exponential backoff ensuring robustness.
Coordinating at scale
With thousands of virtual computers starting or stopping at peak hours, an explosive number of messages flow through the pipeline. To ensure reliability at massive scales, it becomes very crucial for the lambdas to not only effectively communicate with each other, but also coordinate well.
Taking inspiration from the time-tested compare and swap (CMPXCHG) instruction which has existed in microprocessors since Intel 468, TallyPrime on AWS utilizes DynamoDB’s conditional expressions to atomically update status of each virtual computer in the pipeline.
That was just a glimpse of TallyPrime on AWS designed for Reliability and Scalability. TallyPrime on AWS not only meets challenges head-on but pioneers' innovative solutions, setting new benchmarks for cloud-based business solutions in India.
As businesses evolve, TallyPrime on AWS stands as a testament to the blend of technological prowess and visionary innovation.
Key offerings from TallyPrime powered by AWS
- 24*7 access to TallyPrime, from anywhere, anytime
- Affordable and flexible plans starting from 600 INR/Month/User
- Complete privacy and protection of business data guaranteed
- Automatic & encrypted backup of data ensured
- Secure from Virus, malware & ransomware
- Accommodates increased data & user demands easily
- Compliant with Indian statutory laws with locally hosted business data and backup servers








