LLMs generate unconstrained text by default. To manage this, we often provide the target structure upfront and let the models fill it in - this is called Structured Output; It is vital for deterministic LLM workflows, thereby enabling the possibility of reliable production integration. By constraining the model to return responses in a predefined schema, we can reliably parse, validate, and route its outputs within automated pipelines.
This transforms LLM responses from free-form text into structured data that downstream systems can safely consume. For a wide range of tasks, the underlying assumption is that with sufficient context and a strict schema, the model can reason about the problem and produce a correct Structured Output in a single pass.
In theory, this approach looked perfect; in practice, it failed unexpectedly.
When the architecture looked right but the behavior wasn’t
The goal was to build an automated code review system that looks at dependent code for evaluation. This means the system must fetch definitions of classes, functions, and variables being used in the code diff to evaluate.
To support this, the model was given access to tools so whenever it needed more information, it could fetch code, inspect dependencies, or pull surrounding context before reviewing. Combined with a strict schema, this felt ideal. The model could reason as needed and still return production-safe outputs.
However, something odd kept happening during testing. In situations where the surrounding context was clearly missing, the model was expected to invoke the retrieval tool to fetch the required definitions. Instead, it often skipped the tool call entirely and returned a structured response as if it already had enough information. In other words, rather than pausing to reason about the missing context, the model proceeded to produce an answer directly.
At first, the issue seemed to be related to implementation. Perhaps the tool definitions were unclear, or the system prompt did not explicitly instruct the model to avoid hallucinating when context was incomplete. The prompts were revised, tool descriptions were clarified, and stronger instructions were added encouraging the model to call the tool whenever it encountered unknown functions or classes.
Despite these changes, the behavior remained largely unchanged. The model consistently produced well-formatted structured responses, but it did not reliably engage in the intermediate reasoning step that should have triggered a tool call. Instead of explicitly recognizing that context was missing and retrieving it, the model often attempted to complete the task using its own assumptions. The model wasn’t failing to achieve task; It was failing to reason before formatting.
When structured schema skips reasoning
Consider the following code snippet:
# upload_file_function.py
def upload_file(request, storage):
path = request["filename"]
storage.save(path, request["content"])
At first glance, nothing immediately stands out. The function extracts a filename from the request and asks the storage layer to save the file. When the model analyzed this snippet in isolation, the reviews usually looked reasonable. It might occasionally suggest validating user input but rarely flag anything serious.
The missing piece is how storage was expected to behave. That implementation lived in another file:
# storage.py
class Storage:
def save(self, path, content):
full_path = os.path.join(BASE_DIR, path)
write_file(full_path, content)
The moment you see that implementation; the problem becomes obvious - upload_file() function passes user input directly as a file path. The vulnerability isn’t in storage.py; it’s in the function trusting User input without sanitization. But without seeing how save() function worked, the risk didn’t look real.
This is where the Structured workflow kept failing. The model often treated storage.save() function as a safe abstraction and moved on, because the schema pushed it toward producing a finalized answer quickly. Even when tools were available, it didn’t always fetch the implementation before committing to the Structured Output.
The fix: Prompt Chaining
It wasn’t about adding more instructions but breaking the tasks into sub-tasks. The process was split into two smaller prompts - first, let the model leverage the tools provided and reason about the code snippet, followed by extracting the desired structure from the previous inferences’ output.
The core idea here is to break down the problem into smaller problems, where each sub-problem can be solved by individual unique prompts tailored only for that sub-problem and the output generated by solving one problem is fed as input into the subsequent prompts following a chain pattern, also known as Prompt Chaining.
To address the issue discussed, the review pipeline was separated into two prompts. The first prompt is responsible for analyzing the code and identifying potential trust boundaries, external dependencies, and assumptions within the provided snippet. Rather than immediately producing a final structured answer, the model is encouraged to retrieve additional context when required, such as implementations of dependent functions. The second prompt then takes the reasoning and retrieved context from the first step and focuses on extracting the final Structured Output, including the identified vulnerability, its root cause, and the relevant code locations. By separating reasoning from Structured response, the system ensures that the model first gathers sufficient context before generating the final analysis.
"The bug never moved. The model just wasn’t looking for it."
The vulnerability was present in the code from the start, and the system provided all the necessary tools to retrieve the missing context. However, the Structured Output constraint implicitly encouraged the model to finalize an answer early rather than investigate dependencies.
When the model retrieved the Storage.save() function implementation, the trust boundary violation became obvious. But without that retrieval step, the model assumed the abstraction was safe and proceeded with the review.
This revealed an important failure mode: the model wasn’t struggling with bug detection, but with deciding when to gather more information before answering. With prompt chaining, the first step focused only on understanding trust boundaries and hidden assumptions. That reasoning step reliably pulled the storage implementation, and once that context was visible, the vulnerability in the original function became clear. The same can be seen in the screenshot below.
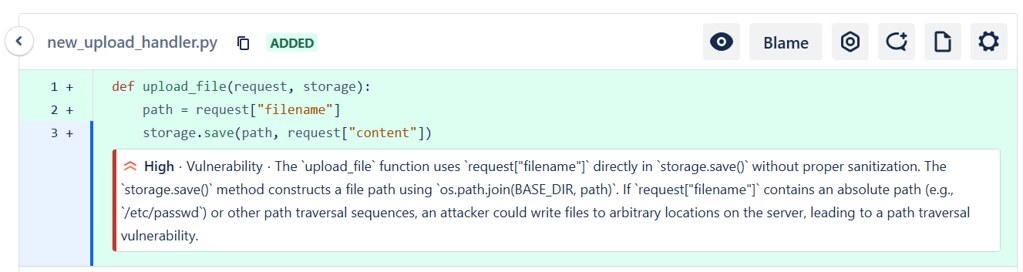
Detection of a path traversal vulnerability caused by unsanitized user-controlled filename input passed to the storage layer.
The takeaway
Structured Output works extremely well for deterministic pipelines, but it also introduces a subtle bias. When the schema is enforced too early, the model optimizes for producing a valid response rather than reasoning towards the right one.
This isn’t a bug. It is the consequence of how constraints shape behavior. When the output format is fixed upfront, the model is implicitly encouraged to fill that structure immediately. Intermediate steps like checking assumptions or invoking tool call gets deprioritized. It is not because the model can’t do them, but the schema creates a bias towards finalization. The result is a system that looks correct on the surface. The responses are well-formatted, parseable, and pipeline-safe. But the reasoning that should precede the answers get quietly suppressed.
Prompt Chaining breaks this pattern by separating what the model needs to figure out from how the output should be structured. The first step reasons freely, invoking tool calls, retrieving context, identifying unknowns. The second step formats and consequently, by the time the schema is enforced, the model has already done the work.
Sometimes improving an LLM system isn’t about better prompts or bigger models, it’s about breaking down the tasks into simpler sub-tasks, through prompt chaining, ensuring both reliability and quality across repeated inferences.













