In the realm of computing, every operation boils down to a dynamic interplay between three core components:
- Workers (CPU Cores/Execution Units): These are the computational engines, the physical or logical units within a CPU that execute instructions. Modern CPUs often feature multiple cores, each capable of acting as an independent worker.
- The Work (Tasks/Operations): This encompasses all the instructions, calculations, and I/O operations that a program needs to perform.
- Resources (Memory, Disk, Network, Data Structures): These are the passive elements that workers interact with or depend on. This includes system hardware (like memory, storage drives, network interfaces) and shared data structures within a program.
The fundamental challenge in optimizing performance is that we typically face constraints: a finite number of workers and limited resource bandwidth. Yet, the demand for "work" is often effectively infinite. The universe's to-do list, it seems, is always longer than our processing power! This inherent imbalance necessitates clever algorithms, and system designs to maximize throughput and responsiveness.
Understanding "Workers": A multi-layered perspective shift
The term "worker" in computing can be a source of confusion because it’s meaning subtly changes depending on the layer of abstraction you're observing. Let's clarify these distinct perspectives:
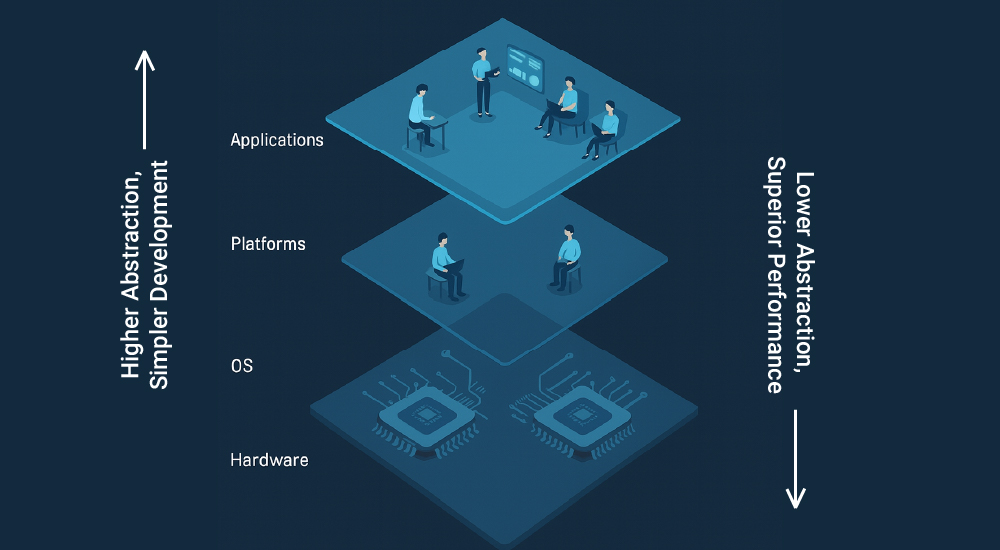
- Hardware perspective (Microprocessor/Microcode):
- Worker: At the very lowest level, the physical CPU core itself is the ultimate worker. It contains execution units (ALUs, FPUs), registers, caches, and control logic driven by microcode (low-level instructions that translate complex CPU instructions into simpler, hardware-executable steps).
- Work: The actual machine code instructions (e.g., ADD, LOAD, STORE) that microcode executes.
- Focus: This level is about the raw ability to execute instructions as fast as possible, managing instruction pipelines and cache coherence.
- Operating System (OS) perspective:
- Worker: From the OS kernel's viewpoint, the physical CPU cores are its workers.
- Work: Threads (and processes, which contain at least one thread) are the schedulable units of work that the OS manages. The OS scheduler's job is to efficiently allocate and switch these "work units" (threads) onto the available "workers" (CPU cores). The OS is the grand choreographer, deciding who gets CPU time.
- Focus: Scheduling, resource allocation, isolation between processes, and providing system services to applications.
- Platform perspective (Runtime/Framework Abstractions):
- Worker: On top of the OS, various programming platforms and runtimes (like Java Virtual Machine, Node.js runtime, Go runtime, .NET CLR) create their own "workers" or scheduling models. These are often user-space threads (sometimes called ‘fibers’ or green threads) or asynchronous event loops.
- Work: The higher-level tasks defined by the platform's concurrency model (e.g., a JavaScript callback in an event loop, a Go’s goroutine). These platform workers are mapped onto a smaller, managed pool of underlying OS threads.
- Focus: Providing a simpler, more abstract, and often more efficient concurrency model for application developers, reducing the direct burden of OS thread management.
- Application programmer's perspective:
- Worker: For someone writing an application, the threads (whether OS threads or platform-managed user-space threads) created within their program are their primary "workers."
- Work: The specific logic, functions, and algorithms of the application itself. The programmer designs how these application-level "workers" will collaborate or operate independently to achieve the application's goals.
- Focus: Implementing application features, managing shared data within the application, and orchestrating application-specific tasks.
This layered understanding is crucial because it clarifies that "worker" isn't a single, monolithic concept but rather an abstraction that changes meaning depending on which layer of the computing stack you're examining. Another important aspect to think of here is each of these layers add a level of simplicity to upper layers, at the same time, they add their management overhead.
“You have to dig deeper to build higher”
The reason why any applications that ‘go deeper’, can extract performance out of it. This allows an application logic, for e.g., to directly execute on the OS thread/scheduler or even hardware physical directly bypassing the management layers.
With our understanding of these multi-layer perspective, we will proceed further with the OS perspective (which is the most common thing and easier to relate for our rest of discussions). So, we will be using the word ‘thread’ largely for ‘worker’.
Threading models: Single-threaded vs. Multi-threaded
The way a program structures its application-level "workers" (threads) significantly impacts its behaviour and performance.
- Single-threaded systems
- Definition: A program or system that has only one main application thread of execution. All tasks are processed sequentially by this single worker (thread).
- How it Works: The single thread picks up one task, executes it to completion, and then moves to the next.
- Pros: Simpler to design, implement, and debug due to a straightforward, predictable flow. Eliminates complexities like race conditions that arise from multiple workers accessing shared data, as only one worker exists.
- Cons: Can lead to unresponsiveness if a single task takes a long time (e.g., waiting for data from a slow network or disk, known as a "blocking I/O operation"). This single thread blocks, halting all other processing for that program. Your program becomes the digital equivalent of a statue, unresponsive to clicks or key presses until it's done. It cannot fully leverage multi-core processors.
- Use Cases: Simple scripts, command-line utilities, or applications where responsiveness isn't paramount and tasks are predominantly short and CPU-bound. Early operating systems like DOS were largely single-threaded.
- Multi-threaded systems
- Definition: A program or system designed to create and manage multiple application threads of execution concurrently (or in parallel on multi-core processors).
- How it Works: The underlying OS or platform runtime efficiently distributes these application threads across available CPU cores. Each thread can potentially execute independently. On a single-core CPU, the OS rapidly switches between threads (context switching), creating the illusion of parallelism. On multi-core CPUs, threads can run genuinely in parallel on different cores.
- Pros:
- Improved responsiveness: If one thread blocks (e.g., waiting for I/O), other threads can continue executing, keeping the application interactive.
- Enhanced performance (Parallelism): Can harness the power of multi-core processors to perform multiple CPU-bound tasks simultaneously, significantly speeding up overall execution.
- Efficient resource utilization: Threads within the same process share resources like memory, making them more lightweight than separate processes.
- Cons:
- Complexity: Introduces challenges like race conditions (multiple threads trying to access/modify shared data at the same time, leading to unpredictable results) and deadlocks (where threads get stuck waiting for each other indefinitely).
- Synchronization overhead: Requires careful management of shared resources using synchronization primitives (like locks) which add performance overhead.
- Debugging difficulty: Non-deterministic nature makes bugs harder to reproduce and fix.
- Use cases: Modern operating systems, web servers, database systems, gaming engines, and almost any high-performance, interactive application.

Concurrency building blocks: The layers of orchestration
Concurrency is built up in layers, from the hardware up to the application. Understanding these building blocks helps clarify how it all fits together.
Layer 1: Hardware/CPU level (The physical workers and atomics)
At the lowest level, the CPU provides the fundamental capabilities for concurrency.
- CPU cores: The true physical "workers" that execute instructions.
- CPU caches: High-speed memory located directly on or very near the CPU cores, used to speed up data access. Managing cache coherence across multiple cores is crucial and handled by hardware.
- Atomic instructions: These are special CPU instructions (e.g., increment, swap, compare-and-swap (CAS)) that are guaranteed to complete without interruption, even if multiple cores try to execute them on the same memory location simultaneously. They are the bedrock upon which all higher-level synchronization primitives are built. If conflicts arise, the hardware ensures one operation succeeds, and others are notified (implicitly or explicitly via status flags) to retry.
Layer 2: Operating System (OS) level (Managing work units and resource access)
The OS acts as the primary orchestrator between applications and hardware.
- Processes: Independent programs with their own isolated memory spaces. The OS manages their creation, scheduling, and termination.
- Threads (OS threads): Lightweight units of execution within a process. The OS schedules these threads onto CPU cores. An OS thread is the smallest unit of work that the OS scheduler can manage independently.
- Schedulers: The part of the OS that decides which thread runs on which CPU core and for how long. It's responsible for context switching (saving the state of a running thread and loading the state of another) to give the illusion of concurrency on single cores or to manage parallelism on multi-core systems.
OS-provided synchronization primitives: Mutexes, semaphores, and condition variables
These are essential tools provided by the OS to application programmers for coordinating access to shared resources and managing thread interactions. While they all serve to synchronize threads, they have distinct purposes. Let's use a common analogy: a bank.
- Mutex (Mutual Exclusion Lock):
- Purpose: To protect a critical section of code or a shared resource, ensuring that only one thread can access it at any given time.
- Mechanism: A thread attempts to "lock" the mutex. If it's unlocked, the thread acquires it and proceeds. If it's locked by another thread, the attempting thread blocks (is put to sleep by the OS) until the mutex is released. When released, one waiting thread is woken up by the OS to acquire the lock.
- Bank Analogy: Imagine a single-occupancy teller window. Only one customer (thread) can be served at a time. If someone is already there, everyone else waits politely in line until the window is free.
- Relationship to Atomics: Mutexes are built upon lower-level atomic instructions. For instance, the very act of checking if a mutex is free and then marking it as locked typically involves an atomic operation.
- Semaphore:
- Purpose: A more generalized signalling mechanism used to control access to a limited number of resources or to signal between threads that an event has occurred.
- Mechanism: A semaphore maintains an internal counter. Threads can perform two operations:
- Wait or acquire: Decrements the counter. If the counter becomes negative, the thread blocks until another thread increments it.
- Signal or release: Increments the counter. If there are threads waiting, one is unblocked.
- Bank analogy: Think of a bank branch that has a limited number of safe deposit box rooms – say, 5 rooms. A semaphore could represent these 5 rooms. Acquire is a customer trying to enter a room; signal is a customer leaving a room. If all 5 rooms are occupied, the 6th customer waits outside. The world, instead of solving its bank queues by building infinite counters, intuitively solved it with a queue system and later a token-based "wait" system (like the numbered tokens you get at some service centers) – because even banks understood the value of waiting efficiently rather than letting everyone storm the counter simultaneously!
- Difference from Mutex: A mutex is essentially a binary semaphore (counter of 0 or 1) used specifically for mutual exclusion. A general semaphore can have any non-negative integer value, allowing more than one thread (up to the counter value) to access a resource concurrently. A thread that signals a semaphore doesn't necessarily have to be the one that previously waited on it.
- Condition variable:
- Purpose: Used to make threads wait until a specific condition becomes true, often in conjunction with a mutex. It doesn't protect data itself but rather facilitates communication and coordination between threads based on shared state.
- Mechanism: A thread that needs a condition to be true will acquire an associated mutex (to protect the shared condition data), check the condition, and if false, it will call wait on the condition variable. This atomically releases the mutex and blocks the thread. When another thread changes the shared state and makes the condition true, it acquires the same mutex, modifies the state, and then calls signal (or broadcast) on the condition variable to wake up one (or all) waiting threads. The woken thread then re-acquires the mutex and re-checks the condition.
- Bank analogy: This is the bank manager announcing, "Attention customers: We've just restocked on that rare foreign currency you wanted! Everyone who was waiting for it, you can come up now!" You don't need the teller window key (mutex) to hear this, but you do need to hear it (the condition being met) to proceed with your transaction.
The critical concept of "context" and context switching overhead
To effectively manage multiple threads or tasks, the OS (or a runtime's scheduler) must be able to pause one thread and resume another. This requires preserving the "state" of the paused thread, known as its context.
What is a Thread's context?
A thread's context is the minimal set of data that fully describes its current state of execution at any given moment. This includes:
- CPU register values: The contents of all general-purpose registers, special-purpose registers and stack pointers.
- Program Counter (PC): The address of the next instruction to be executed.
- Stack Pointer (SP): The current position of the thread's execution stack, which stores local variables, function call information, and return addresses.
- Process Control Block (PCB) / Thread Control Block (TCB) information: Data structures maintained by the OS that hold various administrative details about the thread or process.
The overhead of context switching
When the OS decides to switch from one running thread to another (a context switch), it must perform the following steps:
- Save the context: The OS saves the complete context of the currently running thread into its Thread Control Block (TCB) in memory.
- Load the context: The OS loads the previously saved context of the next thread to be run from its TCB into the CPU's registers.
- Resume execution: The CPU then starts executing instructions from the loaded thread's program counter.
This process, while essential for multitasking, is not free. The act of saving and restoring context is pure overhead, as no "useful" work (application logic) is being done during this time. The overhead includes:
- Direct CPU cycles: The time spent executing the OS kernel code to perform the save/restore operations. This involves memory accesses, which are slower than CPU operations.
- Cache invalidation: When a new thread starts executing, its data and instruction pipelines might not be in the CPU's fast caches (L1, L2, L3). This leads to cache misses, forcing the CPU to fetch data from slower main memory, significantly impacting performance. Similarly, the Translation Lookaside Buffer (TLB), which caches virtual-to-physical memory address mappings, might need to be flushed or updated, leading to more memory access delays.
Think of it like this: the CPU, bless its silicon heart, has to essentially "save its brain state" into a digital folder, then open another folder for the next task. These mental acrobatics aren't free; it's like stopping a high-speed train, changing all the passengers, and then accelerating again. Therefore, algorithms and system designs aim to:
- Minimize context switches: Reduce the frequency of switches, especially for performance-critical paths.
- Reduce context size: Keep the amount of data that needs to be saved/restored small.
Synchronization algorithms: Lock-based, lock-free, and wait-free

Understanding context switch overhead highlights why different synchronization strategies are chosen:
- Lock-based algorithms
- Mechanism (with overhead in mind): When an application thread tries to acquire a lock that's held, the OS deschedules it and performs a context switch to another runnable thread. This avoids busy waiting (spinning) and frees the CPU core for other tasks.
- Trade-off: For long waits or low contention, this is highly efficient because it prevents a CPU core from wasting cycles. However, for very short waits or high contention (where locks are acquired and released rapidly), the overhead of frequent context switches can become a performance bottleneck, potentially making the system slower than if it had just spun for a brief moment.
- Lock-free algorithms (Non-blocking progress)
- Concept: A subset of non-blocking algorithms that guarantees system-wide progress. This means that if multiple threads are attempting to access a shared resource, at least one of them will complete its operation in a finite number of steps, even if other threads are temporarily delayed or suspended. Individual threads might still "starve" (be repeatedly retried/delayed), but the system as a whole always makes progress.
- Mechanism (with overhead in mind): These algorithms typically rely on atomic operations and retries (spinning). An application thread will not block or trigger an OS context switch if its atomic operation fails. Instead, it immediately retries.
- Trade-off: Eliminates context switch overhead during contention, which can be a significant advantage for very short critical sections or high contention scenarios on multi-core systems, where threads are likely to find the resource free quickly or spinning is brief. However, if contention is prolonged or atomic operations repeatedly fail, threads can busy-wait (spin), wasting CPU cycles. This "wasted work" still impacts system throughput, even if it avoids the context switch penalty for individual threads.
- Wait-free algorithms (Strongest guarantee)
- Concept: The strongest form of non-blocking algorithm. It guarantees per-thread progress, meaning every thread attempting an operation on a shared resource will complete its operation in a finite number of steps, regardless of the execution speed or failures (including pre-emption, crashes, or arbitrary delays) of other threads. It's not only about a worker picking up "other work" while waiting; it's about the guaranteed, bounded completion of the specific operation it is performing.
- Mechanism (with overhead in mind): Wait-free algorithms are exceptionally complex to design. They avoid blocking. They often involve more sophisticated atomic operations, explicit "helping" mechanisms (where a thread might help another thread complete its stalled operation to ensure both make progress), or copying data to allow threads to work on private copies before atomically committing.
- Pros:
- Eliminates starvation: The ultimate guarantee of progress for every participating thread. No thread will ever be left waiting indefinitely.
- Predictable prformance: Critical for hard real-time systems where operations must complete within strict, bounded time limits.
- Fault tolerance: A work failing or being delayed cannot prevent other threads from making progress.
- Cons:
- Extremely complex implementation: Designing and verifying wait-free algorithms is notoriously difficult, often requiring deep mathematical proofs of correctness.
- Higher overhead (often): The mechanisms required to provide the wait-free guarantee (e.g., more complex atomic operations, data copying, helping other threads) can sometimes introduce more overhead per operation than simpler lock-free or even well-tuned lock-based algorithms, especially under low contention. This overhead is what you pay for the absolute guarantee.
- Scalability challenges: Can be harder to scale efficiently to very large numbers of cores due to increased cache coherency traffic or helping overhead.
- Industry use: Very niche. Primarily found in highly specialized real-time operating systems, mission-critical embedded systems (e.g., in avionics or medical devices), and academic research where absolute guarantees are non-negotiable.
Anything that feels superior is also extremely complex inside. The wait-free algorithms are not some ‘generalised runtime / frameworks’ that can do the magic. It involves every work to be thought of having breakdowns to do them at different points in time (asynchronous), by different threads/execution units. As per our worker-work-resource analogy, each work to be designed in a way to be executed part-by part by different workers without much context overhead, resources are optimized to be able to allow some work to be paused (when they are in-use), while other work can continue. This allows workers to be always doing ‘some work’ utilizing the overall system processing power. In a simpler way, wait-free is about making worker ‘not wait’ and keeping it occupied with some work, at the cost of some ‘work’ waiting for its dependencies, resources needed to be available to progress. So, you pause / resume the work and not the worker!
Synchronous vs. Asynchronous: Managing flow and latency
The choice between synchronous and asynchronous operations is a design decision directly influenced by context switching costs and the desire for responsiveness as well as the trade-off on various resources (computing resources vs. latency heavy IO resources for example)
- Synchronous operations
- Concept: "Blocking" execution. When a synchronous operation is called, the initiating thread pauses and waits for that operation to complete before proceeding to the next instruction.
- Bank analogy: You walk up to a teller (your thread) and initiate a complex transaction, like a large international money transfer (a long-running I/O operation). You then stand there at the window, absolutely still, watching the teller (the I/O device) process it. You cannot move, talk to anyone else, or do anything else until that single transfer is fully completed. If the teller is slow, you're just stuck.
- Impact on context switching: When a thread performs a synchronous I/O operation, it blocks. The OS will then perform a context switch to another runnable thread. The initial thread will remain "asleep" until the I/O operation completes, at which point the OS will again perform a context switch to reschedule it.
- Consideration: If I/O operations are frequent and long-running, synchronous calls will lead to many context switches, consuming CPU cycles for overhead rather than productive work.
- Asynchronous operations
- Concept: A "non-blocking" execution. An application thread initiates an operation and immediately continues with other tasks. The completion of the asynchronous operation is handled later, typically via callbacks, promises, or async/await syntax. The initiating thread is released to do other work while the I/O operation is handled in the background by dedicated hardware or the OS.
- Bank analogy: You walk up to a teller and initiate that same complex international money transfer. But this time, instead of standing frozen, the teller gives you a receipt or reference number. You then immediately walk away from the window and go do other things – maybe you fill out another form, check your balance at an ATM, or even step outside for some fresh air. You're productive and free while the transfer churns in the background. Later, your phone buzzes (a callback/event), signalling the transfer is complete, and you can then pick up its confirmation and may be do any activity that is a ‘continuation’ of the money transfer (e.g., informing your beneficiary).
- Impact on context switching: Asynchronous patterns effectively manage situations where workers would otherwise be idle due to I/O latency. When an asynchronous I/O operation is initiated, the initiating thread does not block. It can continue its own execution or be context-switched to another task by the OS or a runtime scheduler without waiting for the I/O. When the I/O completes, an event is typically put into a queue, and when the application's main thread (or an event loop thread) processes that event, it can then continue the dependent work. The number of context switches specifically related to the wait for I/O is greatly reduced or avoided from the application's perspective.
- Consideration: This leads to significantly higher CPU utilization and overall responsiveness, as workers are not tied up waiting for slow external operations.
The overhead of management
While we've discussed workers, work, and resources, and the algorithms that try to coordinate them, there's a crucial layer of "management" that also consumes our precious workers. The OS scheduler, the underlying microcode, and even platform runtimes (like the JVM or Node.js) are themselves complex pieces of software that require CPU cycles to perform their duties:
- Deciding which thread runs next.
- Performing context switches.
- Managing memory and caching.
- Orchestrating user-space threads onto OS threads.
- Handling interrupts and system calls.
The overhead of management can make things ineffective, if not handled well. An example of an engineer whose efficiency largely goes into the planning, tracking, reporting of his work to multiple managerial layers can occupy his time significantly for this indirect work and reducing his actual throughput for the actual coding work. Looking at the context switching overhead similarly, frequent distraction can lead to loss of intensity and large amounts of time can go into the context switching.
However, this "management overhead" is a necessary evil. It cannot be zero. Just like in any large organization, having too many managers can become counterproductive. If the managers (OS, runtime) spend too much of the workers' (CPU) time managing rather than letting the workers do the actual work, the overall efficiency plummets. The goal is for the managers to be so efficient and lightweight that their presence enables far more work to be done than the worker’s cycles they consume in management overhead.
That’s why in industries, they say, Thinkers are rare, doers are rarer, and managers are everywhere!
Summary: Optimizing work in a constrained world
Fundamentally, in the world of computing, work is effectively infinite, while the available workers (CPU cores/threads) and resources (memory, disk, network) are inherently limited. The overarching goal of concurrent programming and system design is to maximize the work accomplished: achieving high throughput for backend logic (processing as much data as possible) and ensuring excellent responsiveness for frontend logic (keeping user interfaces fluid and interactive).
This optimization hinges on the efficient utilization of our workers (threads). The ideal scenario is to ensure threads are constantly engaged in meaningful work, with the least possible unproductive time. This means minimizing:
- Spinning: Threads actively consuming CPU cycles while repeatedly checking for a resource, wasting system-wide capacity. It's like impatiently jogging in place while waiting for a bus that's very late.
- Sleeping/blocking: Threads being idled by the OS while waiting for a resource or an I/O operation to complete. While the OS can schedule other processes during this time, it is still "waste" for the specific process / thread that is blocked, as its progress is halted and context switch overhead is incurred.
- Context switching overhead: The unavoidable cost of the OS saving and restoring thread states when switching between tasks. Frequent context switches, even if for "good" reasons, eat into productive CPU time.
- Management overhead: The CPU cycles consumed by the very systems (OS, runtimes, microcode) that manage concurrency, highlighting the need for efficient "managers" that enable more work than they consume.
Sometimes, optimizing for concurrency also means intelligently increasing or logically partitioning resources. Examples include:
- Versioning / Write-ahead systems: Instead of locking, create new versions of data for updates, allowing readers to access older versions without blocking. This can significantly reduce (or bring close to zero) of the reader-writer contentions.
- Increased granularity: Breaking down large, shared resources into smaller, independently manageable units to reduce contention on any single part.
- Lock-free data structures: Designing data structures that allow concurrent access without traditional locks, often leveraging atomic operations.
- Wait-free execution models: Avoiding the worker (who is the costliest resource) needing to halt and still do some other productive work without blocking on an operation to be completed.
The pursuit continues for the ultimate algorithms. What concurrency algorithms can truly achieve is a "holy grail" system that is simultaneously spin-free, lock-free, wait-free, incurs zero/low context-switching and management overhead, thereby fundamentally changing the landscape of how we build high-performance and highly responsive systems. This remains a vibrant area of research and innovation in computing.













