In today’s rapidly evolving cloud environments, incident management remains a significant challenge. Operations teams often rely on Standard Operating Procedures (SOPs), documented steps for handling routine issues — but translating these into automated systems has traditionally required substantial engineering effort.
This article describes how we revolutionized our cloud operations by creating a self-healing system that leverages artificial intelligence to learn from existing knowledge bases, create executable runbooks, and autonomously resolve incidents, keeping humans in the loop for validation.
Challenge: Manual processes in an automated world
Like many organizations, our cloud operations team faced several critical challenges:
- Knowledge silos: Critical operational knowledge trapped in JIRA tickets and wikis.
- Manual execution: Engineers performing repetitive tasks described in SOPs.
- Inconsistent resolution: Similar incidents are being solved differently by different team members.
- Scale limitations: Inability to handle increasing incident volume without adding headcount.
- Cloud expertise: Varying knowledge of cloud fundamentals and exposure to customized business logic implementations across team members, creating dependencies.
Our support team spent approximately 50–60% of their time on routine, repetitive tasks that followed documented procedures. Yet automating these procedures required significant engineering resources, creating a backlog of automation work that could never catch up with the creation of new SOPS in this heavily cloud-dependent world.
Our AI-driven transformation journey
We developed a three-phase approach to create a self-healing system.
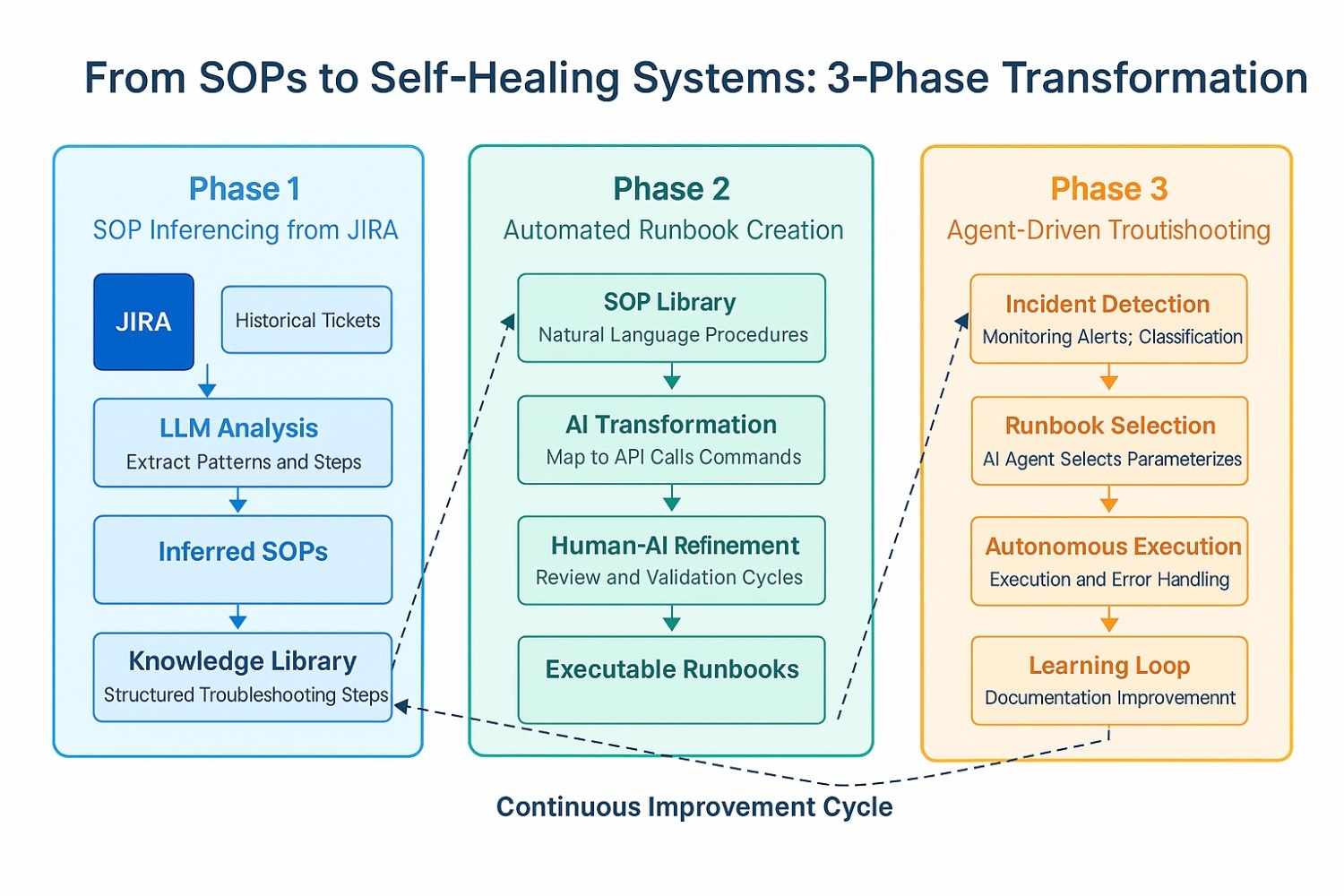
Phase 1: SOP inferencing from JIRA
The first challenge was extracting structured knowledge from our unstructured JIRA tickets. We needed to identify patterns in how our engineers were resolving incidents.
We employed Large Language Models (LLMs) to analyze thousands of historical JIRA tickets, specifically targeting:
- Incident descriptions and symptoms
- Troubleshooting steps taken
- Resolution actions and verification steps
Our system parsed ticket summaries and comments, categorized them by incident type, and extracted the implicit SOPs that engineers would be following.
Phase 2: Automated runbook creation from SOPs
With our newly extracted SOPs, we needed to transform them into executable runbooks. This means:
- Converting narrative descriptions into parameterized steps
- Identifying required permissions and technical dependencies
- Creating error-handling paths
- Generating HTML reports and sending them via email
We designed a specialized AI system using LLMs like Claude that could translate natural language procedures into structured runbooks with standardized inputs, outputs, and error conditions. The system mapped procedure steps to API calls, CLI commands, and monitoring queries.
This phase required close human-AI collaboration:
- The AI system generated initial runbook drafts
- Operations engineers reviewed and refined them
- The system learned from these refinements to improve future drafts
Within one month, we had transformed around 100 SOPs into fully executable runbooks, a task that would have taken our team over a year using traditional methods.
Phase 3: 100% agent-driven troubleshooting
The final phase connected everything into an autonomous troubleshooting system. We created an AI agent framework that could:
- Detect incidents through monitoring alerts
- Classify the incident type
- Recommend the appropriate SOP
- Select the appropriate runbook
- Execute the runbook with proper parameters via a GUI Interface
- Send RCA via Email
Results: A self-healing cloud system
After six months of development and gradual rollout, our system achieved remarkable results:
- 50 % reduction in Mean Time to Resolution (MTTR) for Incidents
- 75 % decrease in manual interventions for routine issues
- 80% accuracy in SOP Recommendation to Engineers
Beyond the statistics, we saw qualitative improvements:
- Fewer Production Logins, which in turn means Higher Security standards.
- Engineers focused on complex problems instead of routine troubleshooting.
- New team members ramped up faster in Operations.
- Root cause analysis became more data-driven.
Future innovations
- Confidence Scoring for SOP Recommendation, to determine whether an incident could be handled autonomously or requires human intervention.
- Automated Incident Resolution by using historical patterns and Log Monitoring to initiate remediation before alerts trigger
- Natural Language Interface to talk to your Cloud Infrastructure.
- Automated Deployments
Our journey from manual SOPs to a self-healing cloud operations platform demonstrates the transformative potential of AI in Cloud operations. The most significant impact hasn’t been technological but cultural, our operations team has transformed from reactive firefighters to proactive architects of resilient systems.
For organizations looking to embark on a similar journey, remember that the goal isn’t to replace human expertise but to amplify it. Start small, focus on high-volume repetitive tasks, and incrementally build trust in your systems. The future of cloud operations isn’t just automated — it’s intelligently autonomous.













